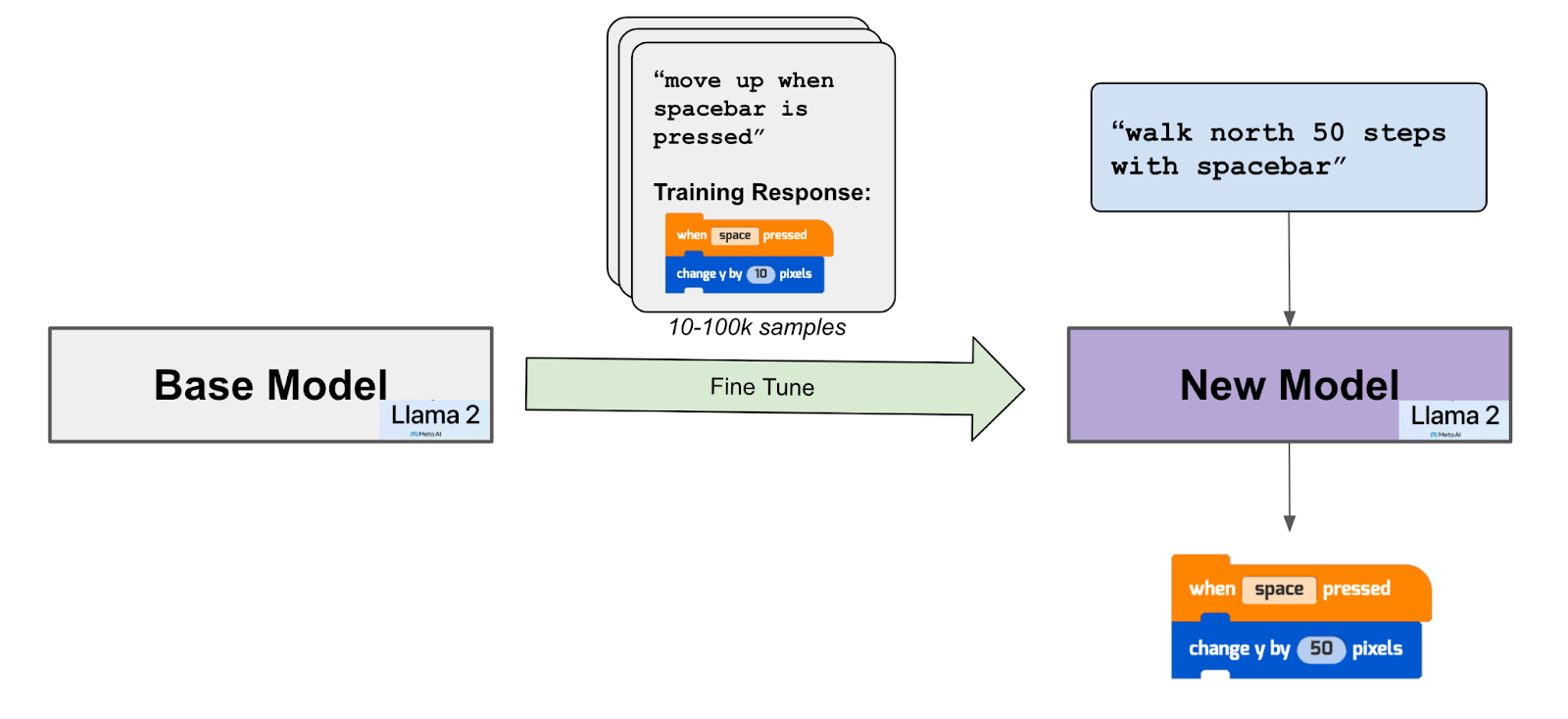
How We Fine Tuned Llama 2 For Our Block Coding Copilot Tynker Blog
In this part we will learn about all the steps required to fine. 13B 70B The Llama 2 LLMs are also based on Googles Transformer architecture but have..
LLaMA-65B and 70B performs optimally when paired with a GPU that has a minimum of 40GB VRAM. More than 48GB VRAM will be needed for 32k context as 16k is the maximum that fits in 2x 4090 2x 24GB see here. Below are the Llama-2 hardware requirements for 4-bit quantization If the 7B Llama-2-13B-German-Assistant-v4-GPTQ model is what youre after. Using llamacpp llama-2-13b-chatggmlv3q4_0bin llama-2-13b-chatggmlv3q8_0bin and llama-2-70b-chatggmlv3q4_0bin from TheBloke MacBook Pro 6-Core Intel Core i7. 1 Backround I would like to run a 70B LLama 2 instance locally not train just run Quantized to 4 bits this is roughly 35GB on HF its actually as..
Chat with Llama 2 70B Clone on GitHub Customize Llamas personality by clicking the settings button. Were currently running evaluation of the Llama 2 70B non chatty version. Open source code Llama 2 Metas AI chatbot is unique because it is open-source. Meta developed and publicly released the Llama 2 family of large language models LLMs a collection of pretrained and..
Token counts refer to pretraining data only All models are trained with a global batch-size of. In order to access models here please visit the Meta website and accept our license terms and. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2. This repo contains GGUF format model files for Metas Llama 2 7B..
How To Finetune Llama 2 Llm

Comments